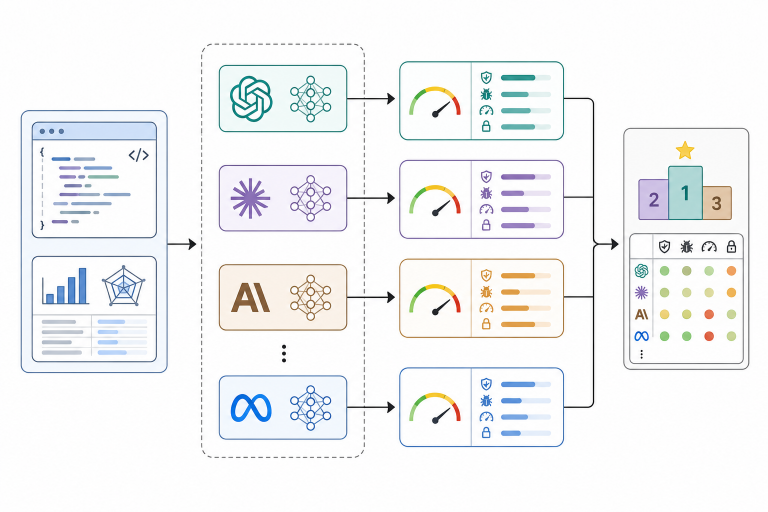
Comparative Analysis of LLMs for Software Quality Assessment via Code and Metrics (2026)
Proceedings of the 18th International Conference on Agents and Artificial Intelligence Authors L. Cernau, A. Dobrescu, Ecaterina Cărbune, Georgiana Asandei Abstract The use of large language models (LLMs) to analyse and identify errors in code is becoming increasingly common among developers. While many studies aim to improve the quality and effectiveness of LLM-generated code,…