home page ->
teaching ->
parallel and distributed programming ->
Lecture 1 - Intro
Lecture 1 - Intro
What?
- concurrent
- there are several tasks in execution at the same moment, that is,
task 2 is started before task 1 ends:
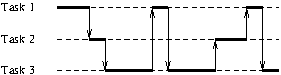
- parallel
- (implies at least a degree of concurrency)
there are several processing units that work simultaneaously,
executing parts of several tasks at the same time.
- distributed
- (implies parallelism) the processing units are spatially distributed.
Why?
- optimize resource utilization
- Historically, the first. While a task was performing
an I/O operation, the CPU was free to process another task. Also, when a user thinks about
what to type next, the CPU is free to handle input from another user.
- increase computing power
- Single-processor systems reach their physical limits,
given by the speed of light (300mm/ns) and the minimum size of components. Even single
processors have been using parallelism between phases of execution (pipeline).
- integrating local systems
- A user may need to access mostly local resources (data),
but may need also some data from other users. For performance (time to access, latency)
and security reasons, it is best to have local data local, but we need a mechanism for
easily (transparently) accessing remota data also.
- redundancy
- We have multiple units able to perform the same task; when one
fails, the others take over. Note that, for software faults (bugs), it is possible that
the backup unit has the same bug and fails, too.
Why not (difficulties)
- increased complexity
- race conditions
- What happens if, while executing an operation, some of the state that is relevant for it, is changed by a concurrent operation?
- deadlocks
- Task A waits for task B to do something, while task B waits for task A to do someother thing.
- non-determinism
- The result of a computation depends on the order of completion of concurrent tasks, which in turn may depend on external factors.
- lack of global state; lack of universal chronology (distributed systems only)
- A process can read a local variable, but cannot read a remote variable (that resides in the
memory of another processor); it can only request the value to be sent, and, by the time the value arrives, the original value may have changed
Clasification
Flynn taxonomy
- SISD (single instruction, single data)
- SIMD (single instruction, multiple data)
- MISD (multiple instruction, single data)
- MIMD (multiple instruction, multiple data)
Shared memory vs message passing
Shared memory
- SMP (symmetrical multi-processing)
- identical processors (cores) accessing the
same main memory
- AMP (asymmetrical multi-processing)
- like SMP, but processors have
different capabilities (for example, only one can request I/O)
- NUMA (non-uniform memory access)
- each processor has a local memory
but can also access a main memory and/or the local memory of the other processors.
Message passing
- cluster
- many computers packed together, maybe linked in a special topology
(star, ring, tree, hyper-cube, etc)
- grid
- multiple computers, maybe of different types and characteristics,
networked together and with a middle-ware that allows treating them as a single system.
Hardware issues — Multi-processors with shared memory
Idea: several CPUs sharing the same RAM. (Note: by CPU, we understand the circuits
that process the instruction flow and execute the arithmetic operations; a PC CPU chip
contains additional circuits, as well, such as the memory cache, memory controller, etc.)
Memory caches
Problems: high memory latency; memory bottleneck
Solution: use per-processor cache
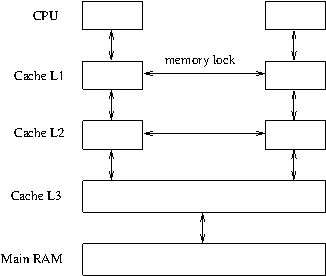
New problem: ensure cache consistency (consider that one CPU modifies a memory location and,
immediately afterwards, another CPU reads the same location).
Solution: cache-to-cache protocol for ensuring consistency. (Locking, cache invalidation,
direct transfer between caches.) However, this means that:
- if multiple CPU access for both read and write the same memory location,
the access is serialized and no speed-up results from multiple cores (moreover,
there is a penalty to be paied for the cache ping-pong);
- the same happens if two variables are placed in distinct memory locations, but in
the same cache line (false sharing).
Note: see false-sharing.cpp and play with the
alignof argument.
Instruction re-ordering
In the beginning, the CPU executed instructions purely sequentially, that is, it started
one instruction only after the previous one was fully completed.
However, each instruction
consists in several steps (fetch the instruction from memory, decode it, compute the
addresses of the operands, get the operands from memory, executing any arithmetic operation,
etc) and sub-steps (a multiplication, for instance, is a complex operation and takes
many clock cycles to complete). Thus, the execution of an instruction takes several
clock cycles to complete.
It is possible, however, to parallelize the stages in instruction execution, for instance,
to fetch the next instrunction while the previous one is being decoded. The result
is a processing pipeline, and thus, at each moment, there are several instruction
in various stages of their execution.
The advantage is that the average execution time per instruction is reduced, but there is
a problem if an instruction needs some results from the previous instruction before those
results are ready. To solve this problem, the solution is to add wait states or to re-order
instructions (so that there is enough time between dependent instructions). Both waits and
re-orderings can be done either by the compiler or by the CPU itself.
The result for the programmer is that instructions can be re-ordered without the programmer
knowing about that. The reordering is never allowed to change the behavior of a single thread,
but can change the behavior in multi-threading contexts. Consider the following code:
bool ready = false;
int result;
Thread 1:
result = <some expression>
ready = true
Thread 2:
while(!ready) {}
use(result)
Because of re-ordering, the above code may not be correct. The compiler or the CPU can re-order
the instructions in Thread 1 because the behavior of thread 1 is not change by that. However,
this makes thread 2 belive the result is ready before actually being so.
Radu-Lucian LUPŞA
2025-10-05