|
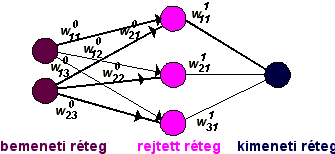
| 2. ábra - egyszerű MLP hálózat |
A tanulmány ismerteti a mesterséges neurális hálózatok fogalmát és néhány tipusát. Viszonylag részletesen bemutatja az alapértelmezésnek tekinthető MLP hálózatot és legfontosabb tanítási algoritmusának a 'backpropagation'-nak néhány fontosabb változatát. Felvázolja az RBF hálózatokat, majd viszonylag részletesen foglalkozik Kohonen ellenőrzés nélküli osztályozásra szolgáló SOM algoritmusával, illetve az ellenőrzött osztályozást végző LVQ algoritmus több válfajával. A továbbiakban irodalmi adatok alapján bemutat néhány GIS alkalmazást, különös hangsúllyal egy csapadék interpolálási esettanulmányra. Az összefoglalás az eddigi eredmények alapján megpróbálja körvonalazni a jövő lehetőségeit.
Mesterséges neurális hálózatok, MLP, backpropagation, RBF, interpolálás, Kohonen réteg, osztályozás, SOM, LVQ, GIS függvények.
A GIS függvényekkel foglalkozó OTKA kutatásom keretében a GIS és az interpolálási módszerek kapcsolatát vizsgáltam (Sárközy, 1999). E munkám irodalom gyűjtése során találkoztam másodszor szakterületi témakörben a mesterséges neurális hálózatokkal. Az első találkozásom talán azért is érdekes, mivel magyar nyelvű cikk volt, mely a mesterséges neurális hálózatok osztályozási felhasználását mutatta be (Barsi, 1997). Nem túl bonyolult meggondolások alapján arra jöttem rá, hogy tulajdonképpen olyan univerzális eszközzel van dolgunk, mely mind a folyamatos, mind a diszkrét interpoláció elvégzésére alkalmas, bizonyos feltételek mellett jobban mint a már ismert módszerek. Ha ehhez még hozzátesszük, hogy a GIS további fejlődése szorosan kapcsolódik az intelligens feladatok megoldásához, azaz a modellező képesség növeléséhez, úgy érthető, hogy egy jó félévre elmerültem a téma megismerésében és az alkalmazási lehetőségek feltárásában. Úgy gondoltam, hogy a sok helyről összegyűjtött ismeretek GIS szempontokat is figyelembe vevő magyar nyelvű összefoglalása hasznos lehet a hazai geomatikai szakmának még akkor is, ha kiváló magyar nyelvű tankönyv is készült a témából a BME Villamosmérnöki és Informatikai kar hallgatói számára (Horváth, 1995).
Mielőtt a részletekre rátérnénk érdemes számba vennünk, hogy a módszer alkalmazási területei elvileg korlátlanok, térbeli interpoláción kívül jó eredménnyel használják a beszéd és alakfelismerésben, robottechnikában, kódolásban és kódok megfejtésében, gépi fordításban, különböző osztályozási feladatokban, optimalizálásokban illetve piaci előrejelzésekben, sőt egyesek szerint a jövő számítógép hardverét is ezen az elven alapulva kell megkonstruálni. Ebből két dolog is következik: egyrészt a szakirodalom általában valamelyik konkrét alkalmazásból indul ki és ezt kell transzformálnunk (ha lehetséges) a saját céljainkra, másfelöl a számtalan alkalmazási terület és alkalmazási transzformáció egyre újabb GIS alkalmazásokat hozhat létre, melyekre természetesen nem térhetünk ki, de reméljük, hogy az új alkalmazások feltárásához jelen cikkünk is hozzájárul.
Az emberi gondolkozás fiziológiájának kutatása során jutottak a kutatók arra a felismerésre, hogy a külvilág ingereit az érzékforrásokból az idegsejtek egy olyan bonyolult hálózaton továbbítják, melyek kereszteződéseiben lévő csomópontok a különböző összeköttetésekből érkező információt feldolgozzák és a feldolgozott értékeket számtalan további idegszálon keresztül újabb csomópontok felé továbbítják, míg el nem érik a kérdéses ingerre adandó válaszért felelős agyi egységeket. Az aktív csomópontokat a kutatók perceptronnak nevezték el.
Hogy a számtalan részfeldolgozáson átesett inger milyen választ vált ki az részben örökletes tényezőktől függ, részben pedig az egyén tapasztalatától illetve a tanulástól. Ez más szóval azt jelenti, hogy bizonyos bemeneti hatásokra a rendszer 'behuzalozottan' (előre programozottan) működik, míg más bemeneti adatok esetén a válasz függ az egyén tapasztalataitól, korától iskolai végzettségétől, stb. A nem orvosi kutatások szempontjából az a lényeges, hogy ez a struktúra adaptív azaz válaszával képes a bemeneti adatokhoz tanulással alkalmazkodni.
|
|
| 2. ábra - egyszerű MLP hálózat |
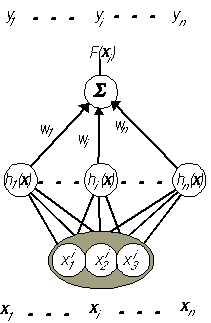
Az 1. ábrán felvázoltunk egy egyszerű MLP tipusú mesterséges neurális hálózatot. Az MLP (Multi Layer Perceptron) tipust a mesterséges neurális hálózatok alapértelmezésének tekinthetjük. Különösen osztályozási feladatokra más hálózatok is ismertek, pld. a Kohonen féle SOM (Önszerveződő Térképek) tipusú, ezekre majd a 2.3 pontban utalunk.
Az MLP hálózatban három réteg tipussal találkozunk. A bemenő réteg annyi elemből (neuronból) áll ahány bemenő változónk van (az ábrán látható példában két bemenő változó szerepel). Rejtett rétegből, elvileg tetszőleges számú lehet, és minden rejtett réteg elvileg tetszés szerinti számú neuront tartalmazhat (rajzunkon egy rejtett réteg szerepel három neuronnal). Kimeneti rétegből mindíg egy van, annyi neuronnal ahány kimeneti változónk van (példánkban egy).
Alapértelmezésben egy adott réteg minden csomópontja össze van kötve a következő, tehát tőle jobbra eső réteg minden csomópontjával.
Ez alól a szabály alól két kivétel fordulhat elő:
az idősorok elemzésére alkalmazott hálózatokban különböző tipusú visszacsatolásokat alkalmaznak. Ezek közül az a legegyszerűbb ha a t időponthoz tartozó kimenetet azonosnak tekintik a t+1 időponthoz tartozó bemenettel;
a szabályos MLP hálózatokban tanításuk után nem feltétlenül minden összeköttetés vesz aktívan részt a kimenet létrehozásában, s azért hogy a felesleges számításokat elkerüljék kidolgoztak olyan 'nyíró' algoritmusokat, melyek segítségével adott adatrendszerhez csökkenteni lehet az összeköttetések számát.
Ahhoz hogy megértsük a hálózat működését először azt kell felvázolnunk, hogy mit is várunk el a hálózattól.
Tételezzük fel, hogy megmérjük egy tó szennyezettségét arányosan elosztva több pontban. Ismerjük a mérési pontok x, y koordinátáit valamint a víz felszinétől számított mélységüket. Ugyanezekben a pontokban ismerjük a tó teljes mélységét is. Arra vagyunk kiváncsiak, hogy olyan pontokban ahol nem mértünk szennyezettséget de (színtvonalas térképről) ismerjük a tó mélységét, tehát adott x, y, felszíntől mért távolság és teljes mélység esetén mennyi lesz a szennyezettség értéke?
Ahhoz hogy ilyen vagy hasonló feladatokra választ kaphassunk először a hálózatot tanítani (train) kell. A tréning abból áll, hogy ismert bemenő adatokból a hálózat működési eredményét (kimenetét) ismert adatokhoz (úgynevezett cél adatokhoz) hasonlítjuk, és ha a mennyiségek eltérnek, úgy igazítjuk a hálózat működését, hogy az eltérés minél gyorsabban eltünjön.
Az előző bekezdés több kérdést is felvet, mindenek előtt azt, hogy mit értünk a hálózat működésén.
A hálózat minden összeköttetéséhez rendeltünk egy 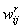 alakú súlyt,
ahol r a réteg sorszáma, i és j pedig az irány kezdő és végpontját jelölő neuronok sorszáma rétegükön belül (a rajzon a zsúfoltság elkerülése érdekében a rétegekre és neuronokra a számokat nem írtuk ki).
alakú súlyt,
ahol r a réteg sorszáma, i és j pedig az irány kezdő és végpontját jelölő neuronok sorszáma rétegükön belül (a rajzon a zsúfoltság elkerülése érdekében a rétegekre és neuronokra a számokat nem írtuk ki).
A bemenő jel megszorzódik a kérdéses irányhoz tartozó súllyal majd belép az irány végén lévő neuronba. A neuronba belépő értékek összegződnek majd az összeget egy transzformáló függvény átalakítja és a következő összeköttetésekre adja, ahol megszorzódnak az irányokhoz tartozó súlyokkal. A folyamat mindaddig folytatódik míg el nem érik a kimeneti neuron(oka)t.
Mit lehet változtatni ezen a hálózaton a célból, hogy a kimenet közeledjen az ismert értékekhez az úgynevezett cél adatokhoz? Természetesen a 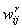 súlyokat. Erre szolgál a backpropagation (visszaterjesztés) nevű algoritmus számtalan változata.
súlyokat. Erre szolgál a backpropagation (visszaterjesztés) nevű algoritmus számtalan változata.
Nem szóltunk még arról, hogy milyen transzformáló függvényeket alkalmaznak. Jobbra dűlt S betűre hasonlí a szigmoid (néha logisztikusnak is hívják), képlete: 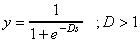 .
A függvény értékei 0 és 1 közt változnak, ha s=0, y=0.5.
.
A függvény értékei 0 és 1 közt változnak, ha s=0, y=0.5.
A másik gyakran használt függvény a tangens hiperbolicus, képlete 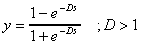 .
Kimeneti értékei -1 és +1 között változnak, ha s=0, y=0.
.
Kimeneti értékei -1 és +1 között változnak, ha s=0, y=0.
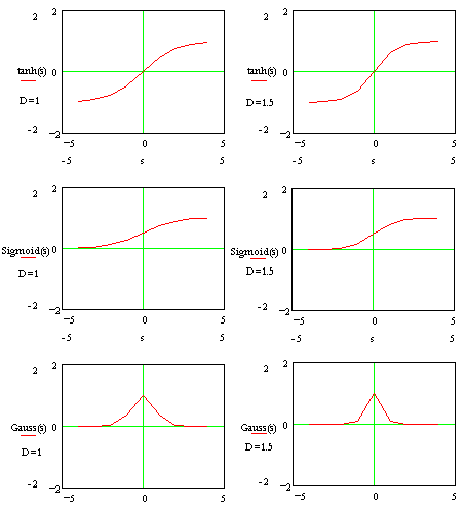
|
| 2. ábra - aktiváló függvények |
Újabban egyre népszerűbb a Gauss féle aktiváló függvény: 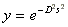 .
Ennek a kimenetei is 0 és 1 között változnak, ha s=0, y=1. A függvények MATHCAD-ban készült
rajzait D=1 és D=1.5
esetére 2. ábrán tüntettük fel. Figyeljük meg, hogy a 'hasznos' bemeneti értékek, azaz amelyek más
bemenethez más kimenetet rendelnek a D értékétől függően kb. 4 és 2.7 között helyezkednek el.
.
Ennek a kimenetei is 0 és 1 között változnak, ha s=0, y=1. A függvények MATHCAD-ban készült
rajzait D=1 és D=1.5
esetére 2. ábrán tüntettük fel. Figyeljük meg, hogy a 'hasznos' bemeneti értékek, azaz amelyek más
bemenethez más kimenetet rendelnek a D értékétől függően kb. 4 és 2.7 között helyezkednek el.
A fenti függvényeket, esetenként keverten is, a rejtett rétegek neuronjaiban alkalmazzák, a bemenő neuronokban nincs transzformáló elem, a kimenő neuronok pedig rendszerint lineáris transzformációt alkalmaznak.
Amint látjuk az aktiváló függvények kimenetei -1, +1, illetve 0, +1 tartományokban működnek, mely értékeket a D-től függően
 2.7-4 körüli bemeneti értéknél érik el, ami azt jelenti, hogy ha a bemenetre abszolút értékre nagyobb számokat adunk (pld 5-öt és 6-ot) a rendszer kimenete lényegében azonos
lesz, más szavakkal a bemenet változásáraa rendszer érzéketlen lesz és a tanulási folyamat lassú lesz és nem fog konvergálni.
2.7-4 körüli bemeneti értéknél érik el, ami azt jelenti, hogy ha a bemenetre abszolút értékre nagyobb számokat adunk (pld 5-öt és 6-ot) a rendszer kimenete lényegében azonos
lesz, más szavakkal a bemenet változásáraa rendszer érzéketlen lesz és a tanulási folyamat lassú lesz és nem fog konvergálni.
Ezt elkerülendő a bemenő adatokat normálni szokták. Ez azt jelenti, hogy minden bemenő adat vektorra (vagy egyszerűen adatoszlopra) elvégzik a következő műveletet: kivonják minden adatból az oszlop középértékét, majd az igy kapott számokat elosztják az oszlop szórásával s-val
(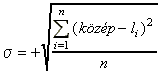 ). A szórás helyett más számmal is oszthatnak a lényeg hogy a normált bemenő adatok az aktiváló függvény hatásos szakaszára essenek.
). A szórás helyett más számmal is oszthatnak a lényeg hogy a normált bemenő adatok az aktiváló függvény hatásos szakaszára essenek.
Ha a kimeneti neuronok lineáris aktiváló függvényűek úgy a kimenetet nem kell skálázni, bár ha a kimeneti értékek túl nagyok numerikus megfontolások ezt is indokolhatják.
Függetlenül attól, hogy milyen szoftvert használunk (lsd, a 3 pontot) a feladat megoldás a következő fő lépésekből áll:
kiválasztjuk a rendelkezésünkre álló ismert bemenő adat - eredmény (céladat) rekordokat (sorokat) és rendszerint valamilyen vesszővel, tabulátorral vagy space-szel elválasztott formátumú ASCII file-t szerkesztünk belőlük valamilyen text editorban. A fájlok fejezetében (az első sorban), a szoftvertől függő módon, meg kell adni, hogy mely oszlopok bemenő adatok és mely oszlopok kimenő adatok;
ha maradtak ismert bemenő adat - kimenő adat rekordok, melyeket nem használtunk a tréning fájlban, úgy ezekből a tréning adat fájlhoz hasonló formátumú teszt adatfájlt hozhatunk létre. A teszt adatok nem javítják a súlyokat, 'csak' tájékoztatják a felhasználót arról, hogy mennyire jól tervezte meg a hálózatát - elfogadhatók-e az eredmények vagy új tréningre (más módszerrel, más induló értékekkel)esetleg új hálózatra van szükség;
a trénig fájl létrehozásával már megterveztük a bemenő és kimenő rétegben található neuronok számát. Ezután már 'csak' azt kel megterveznünk, hogy hány rejtett rétegünk lesz, hány neuron lesz az egyes rétegekben és milyen aktiváló függvényeket alkalmazunk a rejtett rétegek neuronjaiban (feltételeztük, hogy a kimenő réteg neuronjai lineáris aktiváló függvényekkel rendelkeznek).
Sajnos a hálózati elemek számának megbecsülésére eléggé ellentmondásos irodalmi adatokkal találkozunk. Közismert az az állítás, hogy legalább annyi sornak (összetartozó ismert be és kimenő adatnak) kell lenni a tréning adatfájlban ahány súly van a hálózatban. Ezt a tételt azonban egyesek explicit, mások implicit módon cáfolják. Az explicit cáfolat tapasztalati alapon bizonyitja, hogy bizonyos esetekben olyan hálózatok is kiválóan működnek, melyeknek sokkal több súlya van mint ahány tréning sora. Az implicit cáfolat azokban a tételekben és javaslatokban fogalmazódik meg, melyek azt mondják, hogy a legtöbb folytonos függvény közelíthető olyan hálózattal, mely kimenő neuronjai lineárisak, egy rejtett rétege pedig N-1 neuront tartalmaz ahol N a tréning adatok száma. Nem nehéz kimutatni az ellentmondást az előző vastagbetűs állítás és e között, hisz például egy 1 bemenettel, 1 kimenettel és 6 rejtett rétegbeli neuronnal rendelkező hálózatnak 12 súlya van. Egy harmadik állítás szerint a két rejtett rétegű hálózatban N/2+3 rejtett neuron elég a folytonos függvények approximálására. Ez pedig 1 bemenet 1 kimenet és két rétegben elhelyezett 4-4 neuron esetén 24 súlyt jelent míg N=10.
Hogy mégis adjunk valamilyen fogodzkodót azt javasoljuk, hogy minél több tréning adatot használjunk, első kisérletben próbáljuk ki a két réteges megoldást az N/2+3 számú neuronnal, nem kellő konvergencia esetén növeljük a rétegek számát a nélkül, hogy a rejtett neuronok számát növelnénk.
Az igazi megoldást azok az algoritmusok szolgáltatják, melyek a célfüggvény optimális kielégítését vagy az egy rétegen belüli neuronok számának automatikus növelésével érik el mint a Scott Fahlman féle cascad correláció,vagy a rétegeket is meg az elemeket is automatikusan növelik mint a flexnet algoritmus. Ez utóbbi esetében arra is van lehetőség, hogy a létrehozott topológiát tovább tanítsuk valamely backpropagation tanító eljárással.
A hálózat megtervezéséhez tartozik az aktiváló függvények megválasztása is. Bár itt sem lehet általános szabályokat megfogalmazni, az irodalom szerint nem túl zajos adatoknál előnyös a th, míg zajos adatoknál a Gauss függvény alkalmazása;
mielőtt a tanítási folyamatot elindítjuk gondoskodni kell arról, hogy a bemenő adatok és esetleg a kimenő adatok skálázása is megtörténjen. Erre rendszerint egy előfeldolgozási szakaszban kerül sor.
Ezután meg kell választanunk a tanítási módszert, a tanulási sebesség és nyomaték értékét, a kezdeti súlyinicializálás módszerét és a megállási kritériumot (csak a legfontosabb vezérlő beállításokat soroltuk fel, a programok más dolgokat is kérhetnek). Számtalan backpropagation tanulási módszer létezik, ezek közül, sebessége alapján, a quickpropagation használatát javasolhatom. A korszerű algoritmusok lehetővé teszik, hogy a tanulási sebesség és nyomaték a szükségletnek megfelelően automatikusan változzon a tanulási folyamatban. A súlyinicializálást a jobb szoftverek automatikusan végzik, ha nem, be kell adni nekik egy véletlen számot. Igen lényeges, hogy a megállási kritériumra szigorú feltételeket szabjunk, ugyanis a megengedett középhiba értékénél figyelembe kell vennünk a skálázást is.
Fel kell készülnünk arra, hogy egy bonyolultabb hálózat tanítása gyors számítógépen is több órát sőt napot is igénybe vehet. Nem véletlenul futnak az igazán professzionális programcsomagok még ma is csak a UNIX platformokon;
Bár az egész munkát ezért csináljuk, sajnos erről se az irodalom se a szoftverek kézikönyvei sem igazán írnak. A tanított hálózat végső súlyait elmentjuk és ezekkel a súlyokkal a korábbi hálózati topológia alapján kiszámítattjuk az ismeretlen bemeneti értékekhez tartozó kimeneteket. Ez a számítás gyakorlatilag pillanatok alatt kész van. Következésképpen ha a jelenség amit modelleztünk állandó (pld egy kód vagy nyelv) és korlátos is úgy a súlyokat bármikor újabb tanítás nélkül felhasználhatjuk az eredmények meghatározására. Ha a jelenség állandó de igen bonyolult (pld. a terepfelszín), úgy újabb mérési adatok előfordulása esetén ujra taníthatjuk a hálózatot, de kiinduló adatként a már korábban meghatározott súlyokat alkalmazva jelentősen lerövidített idő alatt tudjuk a tanítást végrehajtani.
A legproblematikusabbak a folyamatosan változó jelenségek modellezése, ezeknél gyakran kell a hálózatokat újra tanítani.
Példa hálózatunkban a t.-ik tanuló adat record az 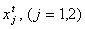 bemenő vektorból és az
bemenő vektorból és az 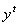 kivánt outputból
áll. Az input balról jobbra terjedve a következő
kimenetet eredményezi:
kivánt outputból
áll. Az input balról jobbra terjedve a következő
kimenetet eredményezi:
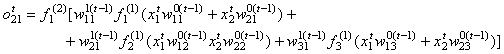
vagy
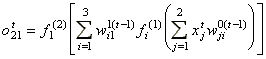
|
(1). |
(Az 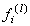 aktiváló függvény az l. (l=0,1,2) réteg i. csomópontjára vonatkozik föntről lefelé értelemben.)
aktiváló függvény az l. (l=0,1,2) réteg i. csomópontjára vonatkozik föntről lefelé értelemben.)
Mivel az 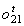 kimenő érték általában nem egyezik a megkivánt
kimenő érték általában nem egyezik a megkivánt 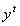 -vel, hogy közelítsünk az egyenlőséghez egy vissza menetben korrigáljuk a hálózati hibákat. Innét kapta a módszer a backpropagation (visszaterjedés) nevet.
-vel, hogy közelítsünk az egyenlőséghez egy vissza menetben korrigáljuk a hálózati hibákat. Innét kapta a módszer a backpropagation (visszaterjedés) nevet.
A kimeneten minimalizálandó hiba függvény a következő:
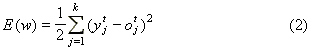
|
, |
ahol k a kimenő csomópontok száma, esetünkben k=1.
Egy nemlineáris függvény minimalizálására használhatjuk a gradiens menti csökkentés módszerét. A 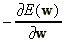 negatív grádiens mutatja a csökkenés pillanatnyi irányát. Ha kis lépésekben az így számított irányok mentén haladunk, úgy remélhetjük, hogy elérjük a globális minimumot. Az irány mentén haladni gyakorlatilag azt jelenti, hogy a súlyokat (a hibafüggvény szempontjából független változókat) a negatív grádiens komponenseivel arányosan változtatjuk. Az h lépésközt az algoritmus tanulási sebességnek hívja.
negatív grádiens mutatja a csökkenés pillanatnyi irányát. Ha kis lépésekben az így számított irányok mentén haladunk, úgy remélhetjük, hogy elérjük a globális minimumot. Az irány mentén haladni gyakorlatilag azt jelenti, hogy a súlyokat (a hibafüggvény szempontjából független változókat) a negatív grádiens komponenseivel arányosan változtatjuk. Az h lépésközt az algoritmus tanulási sebességnek hívja.
|
(3) |
és
|
(4). |
Az összetett függvény parciális deriváltját a 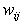 -k szerint a lánc szabály
alkalmazásával kapjuk. Az utolsó, kimenő réteg vonatkozásában, azaz
-k szerint a lánc szabály
alkalmazásával kapjuk. Az utolsó, kimenő réteg vonatkozásában, azaz 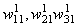 szerint deriválva az eredmény a következő:
szerint deriválva az eredmény a következő:
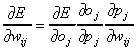
|
(5), |
ahol a kimenő réteg j.-ik csomópontjának a bemenete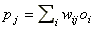 . A deriváltak az (5)-ben az alábbiak:
. A deriváltak az (5)-ben az alábbiak:
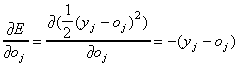
|
, |
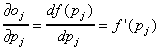
|
, |
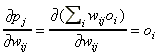
|
. |
A deriváltak (5)-be történő behelyettesítése után a következő kifejezést kapjuk:
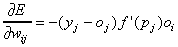
|
(6), |
azaz az utolsó rejtett réteg és a kimenő réteg között a súlyokat az alábbi szabály szerint kell változtatni:
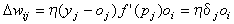
|
(7). |
A 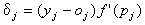 kifejezést a (7)-ben helyi hibának, magát az egyenletet pedig gyakran delta szabálynak hívják. A kifejezésben szereplő tagok részben a tréning
mintából, részben az előző ciklus előreterjedéséből számíthatók. Például az 1. ábrán látható hálózat setében
kifejezést a (7)-ben helyi hibának, magát az egyenletet pedig gyakran delta szabálynak hívják. A kifejezésben szereplő tagok részben a tréning
mintából, részben az előző ciklus előreterjedéséből számíthatók. Például az 1. ábrán látható hálózat setében 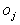 -t az egész (1) képlet eredményeként kapjuk,
-t az egész (1) képlet eredményeként kapjuk, 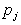 -t a szögletes zárójelben lévő kifejezés adja ugyanebben a képletben,
míg
-t a szögletes zárójelben lévő kifejezés adja ugyanebben a képletben,
míg 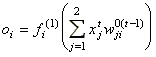 .
.
Mivel a kapott kifejezés csak a kimenő réteg előtti súlyok javítására használható a rejtett rétegekre mutató súlyok javításának meghatározásához 'vissza kell terjeszteni' a hibát.
Legyen n rejtett rétegünk, az (n-1), n rétegek közötti 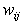 kiszámításához ki kell fejeznünk a helyi hibát az n. réteg j. csomópontján. De e célból már felhasználhatjuk a kimenő réteg csomópontjaira levezetett helyi hibát, hisz a fordított irányú hibaterjedés arányos a követő réteg helyi hibáival. Ha ezeket a csomópontokat k indexszel látjuk el úgy a rejtett réteg helyi hibáira azt kapjuk, hogy
kiszámításához ki kell fejeznünk a helyi hibát az n. réteg j. csomópontján. De e célból már felhasználhatjuk a kimenő réteg csomópontjaira levezetett helyi hibát, hisz a fordított irányú hibaterjedés arányos a követő réteg helyi hibáival. Ha ezeket a csomópontokat k indexszel látjuk el úgy a rejtett réteg helyi hibáira azt kapjuk, hogy
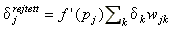
|
(8). |
A fentiek alapján, a súly változásokat ebben az esetben is a (7) szerinti delta szabállyal számíthatjuk, ha a helyi hibákat a (8) szerinti értékükkel vesszük figyelembe.
A backpropagation nagyon érzékeny h értékére, melyet több kisérlet alapján választanak a 0.05, 0.5 tartományból. Egyes algoritmusok képesek dinamikusan változtatni értékét a tanulási folyamatban.
Megkülönböztetünk on-line backpropagation-t, mely minden minta mondat feldolgozása után változtat és lassabb batch változatot, mely az összes minta vizsgálata után csak egyszer változtatja a súlyokat.
Az alábbiakban bemutatunk néhány módosított változatot:
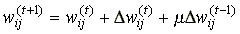
|
(9), |
ahol m értéke a 0, 1 intervallumban vehető fel.
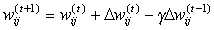
|
(10). |
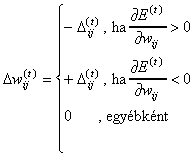
|
(11), |
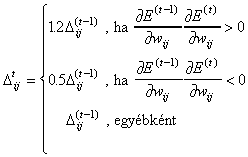
|
(12). |
|
| 3. ábra - RBF hálózat vázlata |
Különleges MLP hálózattipus a RadiálisBázisfüggvényes Hálózat.
Ennek a hálózattipusnak rögzített az architekturája: a hálózatnak csak egy rejtett, egy bemeneti és egy kimeneti rétege van. A 3. ábrán vázolt hálózat bemenő vektora három komponenű , azaz a bemeneti csomópontok száma 3, a hálózatnak egy összegző kimeneti csomópontja és n tanuló mintája van.
A rejtett réteg aktiválása valamilyen radiális bázisfüggvénnyel történik, rendszerint a Gauss függvényt alkalmazzák az alábbi képlet szerint:
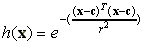
|
(13), |
ahol c jelöli a függvény középpontját, r pedig a sugarát, ha az x input egy dimenziós, akkor c is skalár eltolássá válik:
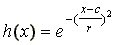
|
(14). |
A kimeneti csomópont vagy egyszerű összegző, vagy sygmoid tipusú aktiváló függvény, ismeretlen b eltolással, mely a kimenő neuron bemenetéhez adódik hozzá.
Csak összegző kimenet esetén a hálózat a következőképpen működik:
Ha a kimeneti csomópont nemlineáris és az ismeretlen b eltolás is jelen van akkor az előbbi megoldás már nem használható, de a megoldás mégis egyszerűbb mint a többréteges hálózatoknál, mivel a delta szabály egyszerű formájában használható. Ebben az esetben a rejtett réteg kevesebb csomóponttal rendelkezik mint a tanuló minták száma, ezért a középpontok meghatározása nem triviális.
Teljesen más elveken működik a Tanuló Vektor Kvantálás (LVQ) módszert realizáló hálózattipus (4. ábra).
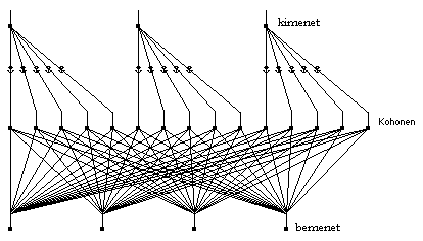
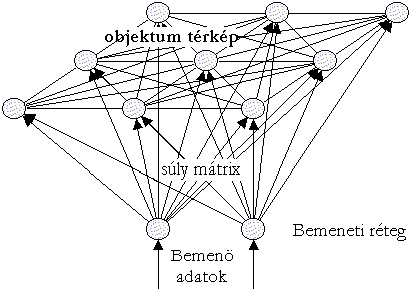
A hálózat három rétegből áll: a normalizált paraméterek bevitelére szolgáló bemenőrétegből, az úgy nevezett Kohonen rétegből és az osztályokat képviselő kimenőrétegből.
A bemenő rétegnek csak akkor van külön funkciója, ha a paraméter vektorok nem egyforma és egységnyi hosszúak, ebben az esetben ugyanis ennek a rétegnek kell elvégezni az egységre normálás feladatát is.
Külön érdeklődésre tarthat számot az u.n Kohonen réteg. A réteg nevét feltalálójáról Teuvo Kohonen finn professzorról nyerte. Kohonen 1982-ben dolgozta ki ezt a rétegtipust felügyelet nélküli klaszterező módszere számára (Self Organizing Maps=SOM), majd a 80-as évek végén ugyanerre a rétegtipusra támaszkodva alkotta meg az LVQ algoritmusokat (négy is van belőlük, C nyelvű forráskódjuk az internetről szabadon letölthető).
A kimeneti réteg egyszerű összegző funkciót lát el.
Részben, hogy a Kohonen réteget jobban megismerjük, részben hogy megismerjünk egy felügyelet nélküli eljárást és végül, hogy előkészítsük az LVQ algoritmust foglaljuk össze röviden a SOM eljárást.
A SOM eljárás lényege hogy az n dimenziós bemenő adatokat szabályos kétdimenziós tömbökre képezi le, és a leképezés eredményét grafikusan és numerikusan ábrázolja.
A 5. ábrán azt a két területfelosztási variációt látjuk, amelyet a korszerű SOM szoftverek (például a NENET nevű win95 alatt működő) használnak.
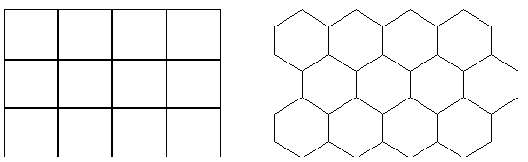
Minden egyes cellához tartozik egy referencia vektor, mely analóg az MLP hálózatoknál megismert súlyokkal. Mivel ezek a súlyok összekapcsolják a kérdéses cellát az összes bemenettel ezért az egyes összeköttetések úgy tekinthetők, mint a kérdéses cella súlyvektorának komponensei. Kézenfekvő tehát, hogy a súlyvektor dimenziója megegyezik a bemenő paramétervektor dimenziójával.
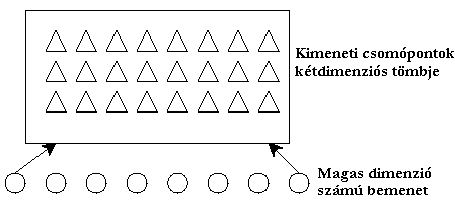
A 6. ábra a kimenő csomópontok kétdimenziós tömbjét állítja szembe a többdimenziós bemenő vektorral.
Hogy a konstrukció még érthetőbb jegyen a 7. ábrán bemutattuk magukat az összeköttetéseket is, igaz hogy csak kétdimenziós bemenő adatok esetére.
Minden bemenő vektorhoz keresünk egy olyan súlyvektort, mely legközelebb van hozzá, azaz melytől számított (euklideszi) távolsága a legkisebb. Képlettel kifejezve:
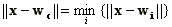
|
(15) , |
ahol c jelenti az x vektort leképező cella indexét.
A tanítási folyamat során mindazok a cellák aktiválódnak a kérdéses x vektortól, melyek bizonyos távolságon belül helyezkednek el a kiválasztott c cellától. A hasznos wi súlyokat a kezdetben tetszőlegesen megválasztott wi(0) értékekből kiindulva a következő tanítási folyamat konvergencia határaként nyerjük:
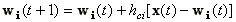
|
(16) , |
ahol hci a szomszédsági függvény. A c cella figyelembe vett szomszédságát (cella számát) Nc(t)-vel jelöljük, ami azt is jelenti, hogy ez a sugár nem állandó, hanem a tanulási folyamat során változik ( t növekedésével csökken). Ha az i indexű cella benne van az Nc(t)-vel jellemzett cellatartományban úgy hci=a(t), ahol (0<a(t)<1) és a függvény monoton csökken.
A tanítás befejezése után a "térkép" a 8. ábrán bemutatott képre lesz hasonló. Ahhoz hogy a tanult hálózatot vizuális interpretálásra fel tudjuk használni manuálisan ki kell választanunk olyan adatokat melyeket a kérdéses feladat kapcsán ismerünk és segítségükkel a tanult térképet fel kell címkéznünk. Ezután a bevitt teljesen ismeretlen adatokat interpolációval illetve extrapolációval értékelni tudjuk a címkézett klaszterekkel fenálló kapcsolatuk alapján.
Hogy egy példát is lássunk, a már hivatkozott NENET program mintapéldája egy technológiai együttesen végrehajtott 5 mérőhely 3480 mérését használta a hálózat tanítására. A tanítás eredményeképpen létrejönnek a cellákhoz rendelt végleges súlyvektorok, melyek egy .map végződésű fájlban kerülnek tárolásra. Ugyanakkor a rendszer kiszámítja az úgy nevezett U mátrixot, mely elemei tartalmazák a cellákhoz tartozó súlyvektorok egységre normált, átlagos távolságát a 6 (négyzetraszter esetén 4) szomszédos súlyvektortól. Az élek színezése a kérdéses él mentén fekvő szomszéd cella súlyától mért távolságot reprezentálja. A példánkra érvényes súlytávolság térkép a 8. ábrán látható. Kis gondolkodás után rájöhetünk arra, hogy tulajdonképpen a jól ismert Voronoi cellák egy speciális ábrázolási formájával állunk szemben. Ha ugyanis a szomszédos cellák középpontját eltolnánk egymástól az élekben kódolt távolságokra és meghúznánk a középpontokat összekötő oldalak felező merőlegeseit, akkor azok kimetszenék a klasszikus Voronoi cellákat. Arról van tehát szó, hogy az algoritmus egy felvett maximális topológiához hozzárendelte a bemenő adatokat legjobban leképező Voronoi cellákat, azaz azokat a súlyvektorokat, melyekhöz egy-egy csoport bemenő vektor közelebb van mint bármely más súlyvektorhoz.

A következő tesztelési fázisban manuális elemzéssel kiválogattak 96 vektort, mely mérésekor a rendszer normálisan üzemelt, 246 hibás működéskor felvett rekordot és 96 olyan rekordot mely mérésekor a rendszer túlmelegedett.
A 9. ábrán azt láthatjuk, hogy hol helyezkednek el és milyen gyakorisággal a normális, hibás és túlmelegedett üzemmódnak megfelelő paramétervektorok.
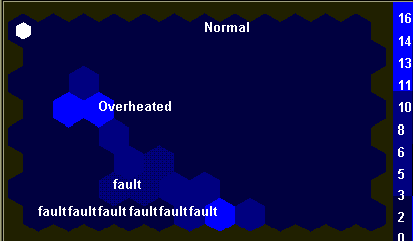
Amint látható, a túlhevített állapot a normális és a hibás működés között helyezkedik el, és interpretálható, hogy átmenetet képez a meghibásodás felé.
Számunkara azonban a SOM azért volt érdekes, mivel elvileg is (a Kohonen réteg bemutatásával) és gyakorlatig is (a kezdeti súlyok kialakításával) átvezet minket Kohonen ellenőrzött osztályozási eljárása a Tanuló Vektor Kvantálás (Learning Vector Quantization = LVQ) tárgyalásába.
A 4. ábrán vázoltuk fel az LVQ osztályozásnál használt hálózatot.
A Kohonen réteg azonos számú cellája reprezentál egy osztályt. Minél több cella tartozik egy osztályhoz annál finomabb az osztályozás. A cella szám növelésének azonban határt szabnak a számítási erőforrások.
Az inicializálási lépésben minden cellához hozzá kell rendelni egy reprezentatív wi súlyvektort az úgy nevezett kódkönyv vektort. Ezeknek a vektoroknak a végleges értékét határozzuk meg a tanítási folyamatban.
A végleges súlyvektorok ismeretében bármely ismeretlen bemeneti vektort ahhoz az osztályhoz rendel az algoritmus amelyhez tartozó valamelyik súlyvektortól számított távolsága minimális.
A súlyok inicializálását elvégezhetjük az előzőekben ismertetett SOM algoritmussal, vagy egyszerűen, biztosan osztályzott bemenő vektorokkal. Hogy ezek a vektorok biztosan mentesek legyenek az osztályozási hibáktól, célszerű előzetesen valamilyen hagyományos osztályozási eljárással (Kohonen javaslata szerint a legközelebbi szomszédság módszerével) minden kiválasztott vektort a többi tanító vektorhoz képest újra osztályozni.
A tanítási folyamatra több alternatív illetve sekvenciálisan alkalmazható algoritmust is kidolgoztak.
Az LVQ1 algoritmus a tanítási folyamatot a következő kifejezésekkel irja le. Jelöljük a kérdéses bemeneti paraméter vektort a t.-ik tanulási ciklusban x(t)-vel, a hozzá legközelebbi súlyvektort (kódkönyvvektort) wc(t)-vel, a monoton csökkenő tanulási sebesség függvényt a(t)-vel, ahol (0<a(t)<1). A tanulási (súlymódosítási) szabály

|
(17), |
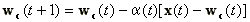
|
(18), |
 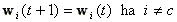
|
(19). |
Az LVQ2.1 algoritmus abban különbözik az LVQ1-től, hogy két legközlebbi súlyvektort módosít egyidejűleg, mégpedig a wj-t, mely az x-el azonos osztályú legközelebbi súly és a wi-t, mely az x-hez legközelebbi különböző osztályú súly. A módosításhoz még az is szükséges, hogy az x "beleessen" az a szélességű ablakba. Ha az x távolságát a wj-től dj-vel, a wi-től pedig di-vel jelöljük akkor a beleesés feltétele, hogy
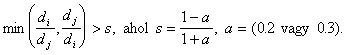
|
. |
A módosított súlyok a következő képletekből számolhatók:
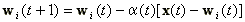
|
(20), |
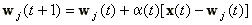
|
(21). |
Az LVQ3 algoritmus továbbra is a (20) és (21) képleteket használja a javításra, ha a két legközelebbi súlyvektor közül az egyik az x osztályához tartozik a másik nem és az x beleesik az ablakba. Arra az esetre vonatkozóan azonban ha mind a két közeli súlyvektor x osztályához tartozik és x belesik az ablakba az LVQ2.1 algoritmus nem rendelkezett, értelemszerűen ebben az esetben csak az egyik, a legközelebbi súlyvektor változtatására került sor. Mivel ez az eset a tanítási folyamat fejlődésével gyakran előfordul az LVQ3 gondoskodik arról, hogy mindkét közeli súly változtatására sor kerüljön.
Abban az esetben tehát, ha mind az x, mind a wi, mind a wj azonos osztályba tartozik
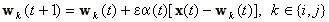
|
(22). |
Az e értékére a kisérleti futtatások alapján 0.1 és 0.5 értékeket javasolnak az algoritmus kidolgozói.
Az előző paragrafusban már említett felügyelet nélküli osztályozó program a NENET win95/NT verziója a http://www.mbnet.fi/~phodju/nenet/nenet.html honlapról szabadon letölthető (újabban bővített változatát kereskedelmi szoftverként árulják).
A tanuló vektor kvantálás (LVQ) legújabb 3.1 verziója az LVQ_PAK programcsomagban tölthető le a http://www.cis.hut.fi/nnrc/nnrc-programs.html címről. A C nyelven írt program néhány függvénye UNIX-os környezetet igényel.
Az általános szoftverek több hálózat tipus különféle módszerrel történő tanítására és tesztelésére alkalmasak.
A legtöbb szoftver munkaállomásokon fut UNIX operációs rendszer alatt. A szoftverek jelentős része kereskedelmi és igen drága, de szerencsére még elég sok egyetemi kutatóhely ingyen bocsájtja a felhasználók rendelkezésére szoftverét.
A szabad szoftverek többsége szintén csak UNIX alatt fut de több letölthető forrásnyelven is (rendszerint C++-ban, de újabban néhány JAVA forrás is megjelent), illetve néhány MS DOS és WINDOWS 95-ös verzióval is találkozunk. Sajnos a DOS exe fájlok kompillálása nem mindíg sikeres pld. a NevProp3 nevű program DOS exéje minden eddig kipróbált adatállománnyal 'elszállt', a következő bekezdésben javasolt FAST programnak pedig a casc2 modulja hoz létre rendszer hibát.
A szabad szoftverek közül kettőre hívjuk fel az olvasó figyelmét, megadva azokat az INTERNET címeket, ahonnan letölthetőek
Először a már idézett FAST 2.2 szoftvert egyetemi verzióját említem, mely különbőző platformokra letölthető a http://www.forwiss.uni-erlangen.de/aknn/Projecte/FAST/ACADEMIC/ könyvtárból. Aki a teljes verzió iránt érdeklődik az intézménye megnevezésével és tevékenységi köre leírásával írjon a következő címre: kindermann@forwiss.uni-erlangen.de. Mivel én csak a szabad 'akadémiai' verziót ismerem az a két hiba a teljes verzióban valószínűleg nem fordul elő, különösen akkor, ha a fordítást C-ből magunk végezzük a saját gépünkre installált kompájlerrel.
Az első hibát már említettük a cascade 2 modullal kapcsolatban. A következő hiba vagy inkább korlátozás, hogy a hibahatárok alapértelmezett értékeit nem lehet megváltoztatni. Sajnos ez a korlátozás lehetetlenné teheti sok interpolálási feladat megoldását. A szoftver számos előnye közül számomra talán az a legfontosabb, hogy a flex modul automatikusan megtervezi a többrétegű hálózatot, a cascor modul pedig egy rejtett réteget tervezve oldja meg a feladatot (sajnos ez a nagyon gyors modul szinte rögtön leáll az alapértelmezésként megadott igen nagy, 0.1 értékű hibaküszöb miatt).
A második szabad program a Stuttgarti Neurális Hálózat Szimulátor vagy eredeti nevén SNNS 4.1 verziója, melynek 1998 elejére készült el windows95/NT-variánsa, mely letölthető a következő ftp címről: ftp://ftp.informatik.uni-stuttgart.de/pub/SNNS/SNNSV4.1-win32/. A windowsos változat probjémája, hogy az MS Windows-hoz készült X-Server programot igényel. Ezek a programok általában nem ingyenesek, a mellékelt Startnet Micro X-Win32 X-Server Demo szabad formájában bizonyos korlátozásokkal használható csak, egy másik szabad X-Serever az alábbi címről tölthető le: http://tnt.microimages.com/www/html/freestuf/.
Az SNNS windows-os változata elég nehezen kezelhető (valószínűleg a X-Server-ek tökéletlensége, valamint az én járatlanságom miatt ezen a felületen). Az azonban már nem az én hibám, hogy nagyon nehéz a paraméterek beállítása, a hálózati jellemzők (pld. aktiváló függvények) bevitele, és hogy szabályos kilépéskor mindíg hibajelzést kapunk.
Az Interneten nagyon sok shareware illetve freeware software található, a shareware-k szinte minden esetben annyira korlátozottak, hogy csak demónak használhatók, a szabad szoftverek pedig rendszerint UNIX-ra iródtak, vagy csak forrásnyelven tölthetők le. Hogy a kompillálási problémák ne zavarják a neurális hálózatok tanulmányozását úgy gondolom, hogy az első próbálkozásokhoz ez a két szoftver elég lesz, utána pedig mindenki szabadon kereshet vagy írhat magának megfelelőbbet.
A neurális hálózatok különleges képessége abban rejlik, hogy képesek mind a folyamatos mind a diszkrét interpolációra és, kisebb megbízhatósággal, extrapolációra. A folyamatos függvények interpolációjáról, már viszonylag részletesen szóltunk, a diszkrét interpolációt - az osztályozást pedig a Kohonen réteget használó hálózatok kapcsán vázoltuk fel. Arról azonban nem szóltunk még, hogy az MLP és RBF hálózatok is használhatók osztályozásra, ha annyi kimeneti csomópontjuk van, ahány osztályt akarunk különválasztani. Ebben az esetben a tanuló adatok egyest tartalmaznak azon a kimeneten, mely osztályhoz a kérdéses, ismert osztályú bemeneti vektor tartozik és zérust az összes többi kimeneten.
A neurális hálózatok számtalan térbeli probléma megoldására alkalmasak. Az alkalmazások azt használják ki, hogy a neurális hálózat a megadott minták alapján feltárja a bemenő adatok és a kimenő értékek közötti kapcsolatot akkor is, ha ez képlettel nem írható le, vagy leírható, de a képlet nem ismert.
Gyakorlatilag tehát arról van szó, hogy a neurális hálózat adott minták alapján elkészíti a kérdéses jelenség modelljét. A modell kimenetén vagy valamely érték szerepelhet, ez az interpoláció illetve függvény megközelítés, vagy valamely osztály, ha a hálózatot osztályozásra használjuk.
Az osztályozásnak azonban nem csak távérzékeléssel készült multisprektális felvételek esetén van jelentősége hanem akkor is, ha a számunkra érdekes jelenséget befolyásoló tényezők (attribútumok) térbeli eloszlása GIS rétegeken van tárolva és arra vagyunk kiváncsiak hogy ezek együttes hatása létrehoz e valamilyen kritikus, beavatkozást igénylő eseményt vagy sem, illetve egyáltalán milyen osztályokba sorolható a közösen fellépő tényezők eredménye.
Az irodalom nem bővelkedik közleményekben a mesterséges neurális hálózatok térbeli interpolációra történő felhasználásáról. Az ismertetendő kutatás (Xingong, 1997) az 1997 októberi GIS/LIS '97 konferencián hangzott el az OHIO állambeli Cincinnatiban.
A kutatás célja Délkarolina állam havi csapadékadatainak interpolálása volt. A tréning adatokat 50 csapadékmérő állomás adatai szolgáltatták, mig az interpolációt 18 tulajdonképpen szintén ismert tesztállomásra végezték. Ebből is látszik, hogy kutatásról van szó, ezért kellett oda interpolálni, ahol már ismert adatok álltak rendelkezésre.
Az interpolációt még négy másik módszerrel is elvégezték, a kontrol módszerek a következők voltak: voronoi cellák, inverz távolság, polynómos interpoláció (trend felület) és krígelés.
A létrehozott neurális hálózat három rétegből állt: a bemenő rétegnek kilenc neuronja volt, az egyetlen rejtett réteget tíz neuron alkotta, a kimenő rétegben egy neuron helyezkedett el.
Igen érdekes a bemenő adatok megválasztása. Az interpolációt három, a vizsgált helyhez legközelebb fekvő esőmérő állomás adataira támaszkodva végezték olymódon, hogy bemenő adatként nem csak az állomások havi csapadék adatait, hanem a vizsgálati helytől mért távolságukat illetve tengerszínt feletti magasságukat is szerepeltették.
Számomra nem teljesen világos, hogy miért nem szerepelt a bemenő adatok között magának a keresett helynek a magassága, esetleg vízszíntes koordinátái.
A magasság és távolság értékeket a 0, 1 tartományba transzformálták. A tréninget a konjugált grádiens módszerrel végezték, a megállás feltétele az volt, hogy a tréning adatok négyzetes középhibája csökkenjen le 0.01 értékre.
A vizsgálat végeredményeképpen megállapították, hogy a neurális hálózatokkal végzett interpoláció minden hónapra megbízható értéket szolgáltatott, míg a többi módszer egy egy hónapban ugyan jobb eredményt nyujtott, de átlagos teljesítményük elmaradt a neurális hálózati interpoláció mögött.
A példa igen jól illusztrálja, hogy a korábban megadott szabályok a tréning adatok és a hálózati súlyok illetve rejtett neuronok száma között nem feltétlenül érvényesülnek a valós hálózatokban. Esetünkben 100 súly van azaz az első szabály szerint 100 tréning adatra volna szükségünk, szemben a ténylegesen meglévő 50-el. A második szabály szerint viszont az egyetlen rejtett rétegben 49 neuronnak kéne lenni ahhoz, hogy a legtöbb folytonos függvényt le tudja képezni 50 tréning adat esetére a hálózat. Persze ez nem zárja ki, hogy a példában szereplő függvény kevesebb neuronnal is leképezhető.
A legtöbb szerző nyomatékosan javasolja a bemenő adatok számának csökkentését. Esetünkben például elképzelhetőnek tartom, hogy a bemenő adatokként x, y, z koordinátákat válasszunk (x, y esetében természetesen súlyponti koordinátákra gondolok), s ugyanakkor növeljük a tréning adatok számát. Ezzel olyan általános szabályt dolgozunk ki, mely nem csak Délkarolinára lesz igaz, hanem arra az egész területre, melyet a tréning adatok behálóznak.
A neurális hálózat feladata az volt, hogy a még fel nem tárt, de mérésekkel valószínűsített lövedékek esetén megbecsülje azok tömegét és mélységét. Mivel a GIS tartalmazza a geofizikai méréseket, a talajtani, geológiai jellemzőket, stb. ezzel megteremti a közös helyen alapuló kapcsolatot a már tanított neurális hálózat bemenő adatai között.
Három osztályba sorolták a lonccal való fertőzőttséget: kevesebb mint 30 növény, 30-től 75 növény, több mint 75 növény jut a vizsgálati cellára. Az MLP hálózat három rétegből állt: bemenő réteg eredetileg 5 csomóponttal, egy rejtett réteg 9 szigmoid aktiváló függvényt tartalmazó csomóponttal és a kimeneti réteg 3 csomóponttal. A 12 mérési helyre támaszkodva 13 tréning adat mondatot vezettek le.
A tréning ellenőrzésére azt a módszert alkalmazták, hogy minden tréning ciklusból kihagytak egy mintamondatot (azaz 13 szor végezték el a tanítást). Azt tapasztalták, hogy az ellenőrzés eredményei csak négy mondat vonatkozásában voltak megnyugtatóak. Mivel ezt az eredményt nem tartották kielégítőnek megváltoztatták a bemenő adatokat: elhagyták a vizsgált területen jelentéktelennek tünő lejtést és helyette bevezették az erdő háborítottság fogalmát (erdő széle, utak, ösvények épületek, stb.), mivel szakmailag bizonyítható, hogy a háborítottság elősegíti a gyom terjedését. Az új bemenő adatokkal a tesztelés mind a 13 esetre teljes hibátlanságot mutatott.
A tanulmány fő érdekessége számomra abban rejlik, hogy szemléletesen mutat be egy olyan térbeli modellt, mely eredményül osztályokat szolgáltat. Hátránya a tanulmánynak, hogy nem tér ki a neurális hálózati szoftver és a térinformatikai szoftver összekapcsolására.

|
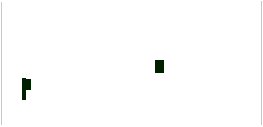
|
| a. | b. |
A tanuló értékeket az a ábra bal alsó sarkában tálálható clusterből nyerték. A két ábra foltjai ugyan jól illeszkednek egymásra, de egyelőre nem értjük, hogy miért lettek a neurális hálózat által osztályozott területek nagyobbak és szabályosabbak mint az eredetileg ismertek.
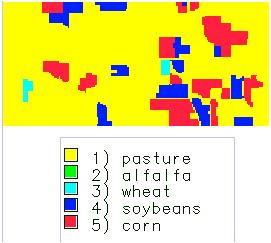
Ha azonban megnézzük a 11.ábrán látható C réteget, amely tartalmazza a tényleges táblákat, akkor rögtön szembetűnik, hogy a neurális hálózat osztályozása a táblán belül talált kritikus értékeket kiterjesztette az egész táblára, esetünkben, a jelkulcs szerint, búzatáblára.
Amint az olvasó látja, a példák között nem foglalkoztunk a neurális hálózatok távérzékelési hasznosításának kérdéseivel, amit a terjedelmi korlatákon kívül elsősorban az indokolhat, hogy ezen a területen bőven találhatunk érett alkalmazásokat ismertető cikkeket még magyarul is, pld. (Barsi, 1997, 1998).
(Barsi, 1997) Barsi Árpád: Landsat-felvétel tematikus osztályozása neurális hálózattal. Geodézia és Kartográfia, 1997/4, pp. 21-28.
(Barsi, 1998) Barsi Árpád: Felszínborítottság térképezése neuro-fuzzy módszerrel GIS környezetben. Geodézia és Kartográfia, 1998/6, pp. 10-15.
(Deadman & Gimblett, 1997) P. Deadman, R. Gimblett: Application of neural net based techniques to vegetation management plan development. AI Applications. Fall, 1997. Megtalálható az interneten a 'http://nexus.srnr.arizona.edu/~gimblett/aidead97.html' címen
(Foley et al., 1998) J. Fley, M. Gifford, S. Millhouse, L. Helms: Ordnance and Explosives (OE) program Geographic Information System (GIS) and Knowledge Base (KB). Elektronikus publikáció a 'http://www.scainc.com/oegiskb.htm' címen.
(Horváth, 1995) Horváth G. (szerk.): Neurális hálózatok és műszaki alkalmazásaik. BME Villamosmérnöki és Informatikai Kar, Műszer és Méréstechnika Tanszék. Műegyetemi Kiadó, 1995.
(Muttiah et al.,1996) R. Muttiah, R. Srinivasan, B. Engel: Development and Application of Neural Network Interface for GRASS GIS. Third International Conference/Workshop on Integrating GIS and Environmental Modeling. Santa Fe, New Mexico, January 21-25, 1996. Proceedings CD rom..
(Sárközy, 1999) Ferenc Sárközy: GIS functions - interpolation. Periodica Polytechnica ser. Civil Engineering. vol 43, No. 1. 1999 (nyomdában). A cikk elektronikus verziója megtalálható a 'http://www.agt.bme.hu/public_e/funcint/funcint.html'internet címen.
(Xingong,1997) Xingong Li: Development of a neural network spatial interpolator for precipitation estimation. GIS/LIS '97 Annual Conference October 28-30, 1997.Cincinnati, Ohio. Proceedings CD rom. pp. 667-676.