home page ->
teaching ->
parallel and distributed programming ->
Lecture 2 - handling concurrency
Lecture 2 - Handling concurrency
Processes and threads
See a C++ example and a Java example
with threads and performance measurement.
See also a classical pitfall regarding closures in C#, in a threading context.
A thread has a current instruction and a calling stack. In more details, it has the following attributes:
- The pointer to the current instruction (IP register);
- The stack of nested function calls (with the return address from each function to its caller);
- The local variables and temporaries for each active function.
At each moment, a thread can:
- run on one of the CPUs,
- be suspended, waiting for a CPU to become available,
- sleep, waiting for some external operation to complete.
This means that each CPU executes instructions from one thread until it either launches
a blocking operation (read from a file or from network), its time slice expires, or some
higher piority thread becomes runable. At that point,
the operation system is invoked (by the read syscall, by the timer interrupt, or by the
device driver interrupt), saves the registers of the current thread, including the
instruction pointer (IP) and the stack pointer (SP), and loads the registers
for the next scheduled thread. The last operation effectively restores the
context of that thread and jumps to it.
It should be noted that a context switch (jumping from one thread to another) is quite
an expensive operation, because it consists in some hundreds of instrunctions, and may
invalidate a lot of the CPU cache.
Creation and termination of a thread is also expensive.
A process can have one or more threads executing for it. The memory and the
opened files are per process.
Mutual exclusion problem
The problem
Two threads walk into a bar. The bartender says:
Go I don't away! want a race to get condition last like I time had.
Consider several threads, where each of them adds a value to a shared sum. For instance, each thread processes a sale at a supermarket, and each adds the sale value
to the total amount of money the supermarket has.
Since the addition itself is done in some register of the CPU, it is possible to have the following timeline:
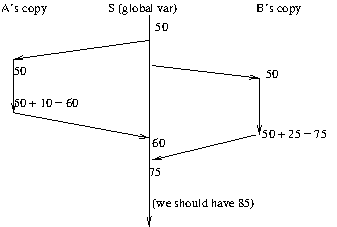
So, thread B computes the sum based on the original value of S, not the one computed by thread A, and overwrites the value computed by A.
What we should have is to execute the addition either fully by A and then fully by B, or viceversa; but not overlapped.
Atomic operations
These are simple operations, on simple types (integers, booleans, pointers), that are guaranteed
to execute atomically. They have hardware support in the CPU. They need to be coupled with
memory fences — directives to the compiler and CPU to refrain from performing some
re-orderings.
Operations:
- increment / decrement;
- add / substract a given value;
- and / or / xor with a given value;
- set (store) / get (load) with a given value;
- exchange - store a value and retrieving the previous value;
- compare-and-exchange: compare the atomic variable with a given value and, if equal,
set it to another value; also, return the old value.
See:
Uses:
- Simple atomic add/substract values;
- Basic block to implement spinlocks;
- Compare and exchange: compute new value, then replace current value with new value if the current value
is still the old one. See also ABA problem - what if the value is modified twice or more times between read and compa
Notes about memory order (see C++ atomic variables):
- relaxed - just for the atomic operation, not for memory barriers
- release + aquire - the producer thread writes some results to some shared variables,
and then writes an atomic variable with memory order release; a consumer thread verifies if the atomic variable has the expected value,
reading with memory order aquire
- sequencial consistency - in addition to aquire-release semantics, all these atomic operations appear in the same total order to all threads.
Notes about compare-and-exchange:
- It can be used to implement more complex operations on a shared variable:
one starts by storing the original value, then compute the new value, then compare and exchange
the old value with the new value. If anyone else modified the shared variable, the compare-and-exchange operation will reject the update
and the operation can restart.
- This makes the basics of lock-free programming, where no thread has to wait for others to do anything. It is a trade-off though: while no thread
is blocked, operations may have to be re-started several times, thus consuming more CPU time.
- ABA problem: if two or more operations are performed between a read and the subsequent compare-and-exchange, and those operations end up in writing
a value equal to the origin, then the compare-and-exchange operation will succeed. If the shared variable contains all relevant information, it is fine;
otherwise, the result is wrong.
- weak and strong forms: on some architectures, under rare circumstances, the compare-and-exchange operation may fail spuriously
(that is, even though the variable has the expected value); for that reason,
it is called compare-and-exchange-week. Since, in most cases,
the compare-and-exchange is inside a loop that re-tries until successful, this is enough; for other cases, a compare-and-exchange-strong
form is provided that doesn't have this problem, but comes at a bit higher cost.
Mutexes
A mutex can be hold by a single thread at a time. If a second thread tries to get the mutex,
it waits until the mutex is released by the first thread.
A mutex can be implemented as a spin-lock (via atomic operations), or by going
through the operating system (which puts the thread to sleep until the mutex is freed).
Mutexes are used to prevent simultaneous access to the same data.
Each mutex should have an associate invariant that holds as long as nobody holds that mutex:
- some variables are guaranteed not to change;
- some consistency conditions are guaranteed to hold.
Mutexes in various languages:
Invariants in single-threaded applications
In a single threaded program, when a function begins execution,
it assumes some pre-conditions are met. For instance:
// preconditions:
// - a, b and result are valid vectors
// - vectors a and b are sorted in increasing order
// - vector result is not an alias to either a or b
// post-conditions:
// - a, b and result are valid vectors
// - vector result contains all the elements in a and b, each having
// the multiplicity equal to the sum of its multiplicities in a and b
// - vector result is sorted
// - vectors a and b are not modified
// - no other program state is modified
void merge(vector const& a, vector const& b, vector&result);
If the pre-conditions are met, the function promises to deliver the specified
post-conditions.
If the pre-conditions are not met, the behavior of the function is undefined
(anything may happen, including crashing, corrupting other data, infinite loops, etc).
In conjunction with classes, we have the concept of a class invariant:
a condition that is satisfied by the member data of the class, whenever no member function
is in execution.
Any public member function assumes, among its pre-conditions,
that the invariant of its class is satisfied. Also, any public member function
promises, among its post-conditions, to satisfy the class invariant.
At a larger scale, there are various invariants satisfied by subsets of the application
variables. Consider the case of a bank accounts application: an invariant would be that
the account balances and history all reflect the same set of processed transactions
(the balance of an account an is the sum of all transactions in the account history,
and if a transaction appears on the debited account, it appears also on the credited
account, and viceversa).
At the beginning of certain functions (for instance, those performing a money
transfer, as above), we assume some invariant is satisfied; the same invariant
shall be satisifed in the end. Then, sub-functions are invoked, concerned
with sub-aspects of the computation to be done; the precise pre- and post-conditions
for those functions should be part of their design; however, many bugs arise from a
misunderstanding regarding those per- and post-conditions (in other words, the
exact responsability of each function).
Note that sometimes the history is not kept as a physical variable in the system;
nevertheless, we could think of it as if it were really there.
An implicit assumption in a single-threaded program is that nobody changes a variable
unless explicit instructions for that exist in the currently executing function.
Invariants in multi-threaded applications
In multi-threaded applications, it is hard to know when it is safe to assume a certain
invariant and when it is safe to assume that a certain variable is not modified.
This is the role of mutexes: a mutex protects certain invariants involving certain
variables. When a function aquires a mutex, it can rely that:
- the invariants are satisfied at the point the mutex is aquired;
- no other thread will modify the variables before the mutex is released.
The function must re-establish the invariant before releasing the mutex.
The above also implies that, in order to modify a variable, a function must
make sure it (or its callers) hold all mutexes that protect invariants concerning
that variable.
Read-write (shared) mutexes
There are two use cases concerning the invariants:
- a function changes some variables, it needs to ensure that the invariant holds when
it begins, promises to re-establish the invariant, but it will violate the invariant
during its execution. Therefore, during the execution, nobody else can be allowed
to see the variables involved in the invariant.
- a function needs to ensure that some invariant is satisfied during its execution,
but it does not change any variable involving in that invariant.
A thread doing case 1 above is incompatible with any other thread accessing any of the
variables involved in the invariant. A thread doing case 2 above, however, is compatible
with any number of threads doing case 2 (but not with one doing 1).
For this reason, we have read-write mutexes, also called shared mutexes.
Such a mutex can be locked in 2 modes:
- exclusive lock or write lock, which is incompatible with any other
thread locking the mutex;
- shared lock or read lock, which is incompatible with any other thread
locking in exclusive mode the same mutex, but is compatible with any number
of threads holding the mutex in shared mode.
Caveat: the implementation of a shared mutex must deal with the following dilemma:
Suppose several readers hold the mutex in shared mode, and a new (writer) thread
attempts to lock it in exclusive mode. What to do if, before all the readers finish,
a new reader comes in? If we allow the reader, we run the risk of starving the writer
(if we have enough readers to keep at least one active one for a long time).
If we deny the reader, we miss a parallelizing opportunity.
Note: starvation is the situation that occurs when a thread cannot advance because
it is always waiting for a resource that it cannot get because, although no thread holds
the resource continuously, there is always a thread that demands the resource and has a
higher priority than the starving one. The usual solution is to allocate resources on
a first-in first-out basis, so that each thread waiting on a resource eventually gets its turn to it.
On the other hand, a deadlock is a situation where two or more threads cannot advance
because each waits for another one to advance.
On recursive mutexes
A recursive mutex allows a lock operation to succeed if the mutex is already locked
by the same thread. The mutex must be unlocked the same number of times it was locked.
The problem with recursive mutexes is that, if a function attempting to
aquire a mutex cannot determine if the mutex is alreay locked or not, will not be able
to determine if the invariant protected by the mutex holds or not immediately after
the mutex is aquired. On the other hand, if the function can determine if the mutex
is already locked, it has no need for a recursive mutex.
Radu-Lucian LUPŞA
2024-10-20